

电话:13051199966
地址:北京市朝阳区清林路1号世茂奥临花园
智輅|星尘数据:以MorningStar加速AI创新

在大模型时代,各行业都需要基于自身数据打造超级员工,以提高企业的生产效率。模型和算力可以购买,但数据需要精细化、全流程的管理,才能释放真正的价值。企业需要搭建可发现、可管理、可协作、可迭代的数据管道,才具备获取数据、生产数据、持续迭代数据的能力,促进内部以数据为中心的协作,从而在AI 2.0时代中获得核心竞争力。

在这样的背景下,深耕数据科技领域的资深玩家——星尘数据在近日发布了专注于数据价值发现的平台MorningStar,旨在打通AI算法从训练到生产全链路中的数据管理、迭代、优化、挖掘等闭环链路。发布会间隙,星尘数据创始人&CEO章磊向《汽车观察》记者畅谈了企业数据管理在人工智能2.0时代的意义、行业痛点以及解决方案。
人工智能迎来四大发展趋势
近年来,AI算法经历了多个发展阶段,都和数据的突破息息相关。章磊指出,人工智能迎来四个发展趋势。
第一个趋势是:数据技术驱动人工智能发展三次变革。“数据技术是推动人工智能发展变革的核心原因。2009年,ImageNet项目充分展示了深度神经网络的潜力。该项目不仅证实了深度学习模型处理复杂视觉任务的能力,也凸显了大规模标注数据在训练高效模型中的重要性。2017年,Transformer架构的推出及其在BERT和GPT等模型中的应用,带来了另一次飞跃。这一阶段的关键创新在于能够利用全网数据进行大规模并行训练,显著提升了模型的理解和生成能力。2022年,大语言模型进一步证明了数据策略和数据质量对于模型的重要性。”章磊解释。
第二个趋势是:数据管理职责细分化,企业数据债亟需消除。章磊认为,数据管理正在经历职责细分化,从以个人为中心的协作将转变为以数据为中心的协作。AI数据全生命周期管理,可促进多角色的数据统一认知。
“过去,我们需要算法部门、业务部门、产品部门和技术部门等多个部门共同协调和统一。在从数据到算法的流程中,由于中间层的存在,沟通效率往往降低。未来的企业需要一个让所有参与者站在同一个视角下协作的平台。在AI研发的不同阶段,如早期、中期和晚期,算法的视角、理念和认知是不断变化的。同时,部门之间,如服务和运营部与项目执行部,以及人与人之间,如算法工程师之间,存在认知鸿沟,导致很多数据的语义背景信息难以通过文档或邮件清晰传达,因此,我们需要一个以数据为中心的载体,来清晰表达数据背后的语义信息。”章磊表示。

第三个趋势是:AI生态发展将以数据闭环为中心。章磊坦言,过去以模型研发为中心,数据相对固定,而随着模型不断迭代,模型效果提升主要来自数据,转向Data-centric AI。以大模型为例,模型架构变化不大,真正变化的是背后的数据。以GPT为例,从GPT2到GPT3,数据集的量从40GB增加到45TB。而从GPT3到GPT4,不再是数据量的增加,而是全网数据的利用,包括数据训练策略、数据清洗、数据整理、数据分布以及人类反馈等方面。
在章磊看来,未来算法的发展将类似于互联网时代的快速迭代,这种迭代不是改变模型架构,而是优化数据。
第四个趋势是:通过AI打造超级员工,企业生产力将十倍提速。章磊指出,通过AI打造企业的超级员工,将使企业成为24小时不停运转的超级大脑,所有员工围绕这个大脑不断沉淀数据和大模型,然后将大模型的能力赋能给企业。
数据成为AI 2.0时代差异化竞争力
章磊介绍,自2022年以来,大模型驱动企业经营效率提升10倍已成为可能,关键在于企业数据能不能成功打造超级员工。“超级员工可以帮助企业完成研发、代理、销售产品、财务等任务,但并非所有数据都同等重要,只有那些黄金数据集才能有效帮助模型迭代。如何准备这些数据集已成为自动驾驶公司、车厂和各类企业的核心竞争力。”
MorningStar的设计灵感源自人的海马体。在章磊看来,只有“记忆”是属于企业自己的,企业的核心知识、信息和数据就像人的海马体一样,应该存在于企业内部的固定数据管理系统中。
随着大模型的发展,企业员工数量可能会减少,企业只有自身具备沉淀私域高质量数据的能力,即可直接用于生成超级员工的数据,才能获得市场竞争的核心优势。“在AI 2.0 时代,掌握自己的数据就是掌握自己的模型。企业数据价值的核心在于定义、管理和迭代。”章磊说道。
章磊认为,数据管理的首要要求是可管理性;其次是可挖掘性,即在数据中挖掘出对模型有价值的信息;第三是可迭代性,数据需要根据模型和用户反馈不断变化;第四是可优化性,数据应不断优化并协同工作,以打造真正属于企业的数据资产。
MorningStar打通AI数据全生命周期管理
AI的变革凸显了数据技术在推动机器学习算法进步方面的关键作用。据章磊介绍,算法开发过程中有80%的工作与数据相关。一个算法的上线部署需要经历需求定义、方案制定、数据采集、数据标注、模型设计、训练、指标测试、推理优化等等。在各个环节中,各个角色跨组织协同会导致企业数据债(指的是企业当前状态与最大化数据价值之间的差距,包含算法和其他部门的认知差别、项目时间上的认知差别、文档和数据语义的差距、不同数据集定义之间的差距等)的产生。数据债不仅会导致数据价值无法释放,运营成本不断增加,还会影响模型的上线和迭代效率。
正是基于对行业的深刻认识,为了帮助企业建立高效的数据闭环系统,实现数据价值最大化和模型效果最优化,星尘数据开发了满足AI 2.0时代数据管理需求的全能工具——MorningStar。章磊表示:“MorningStar专注于发现数据价值,加速模型迭代,为AI 2.0打造以数据为中心的协作环境,消除数据债。”
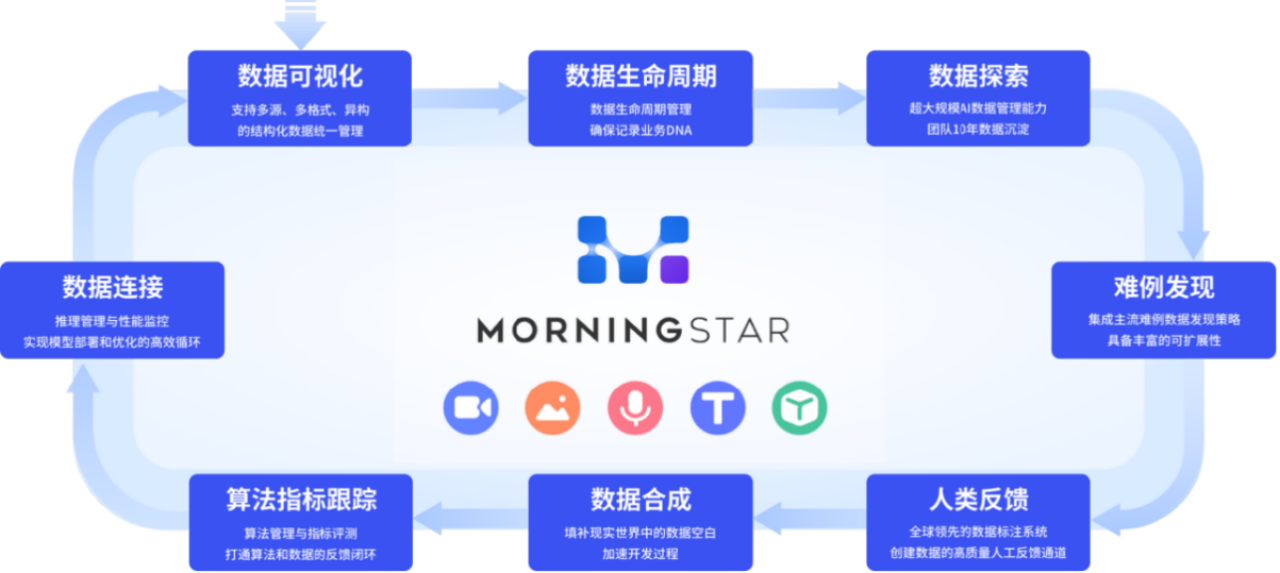
▲MorningStar数据闭环
据章磊介绍,MorningStar是目前市面上唯一一个专为AI 2.0时代企业打造的数据闭环产品,覆盖AI算法从训练到生产全链路中的数据管理、迭代、优化、挖掘等闭环链路。
据悉,在机器学习中,模型在整个流程中所占比重很少,算法工程师绝大部分时间都是花在思考业务、数据标注和数据分析上,以提高模型的泛化性。算法工程师需要耗费大量的时间和精力仔细研究数据,找出异常之处,了解数据规律,反复编排流程,比较版本差异,以提高模型的泛化性,达到最佳效果。如:难以直观看到数据分布,效率低;数据语义缺乏记录,难复现;数据指标不完善,难挖掘;数据量巨大,检索困难......
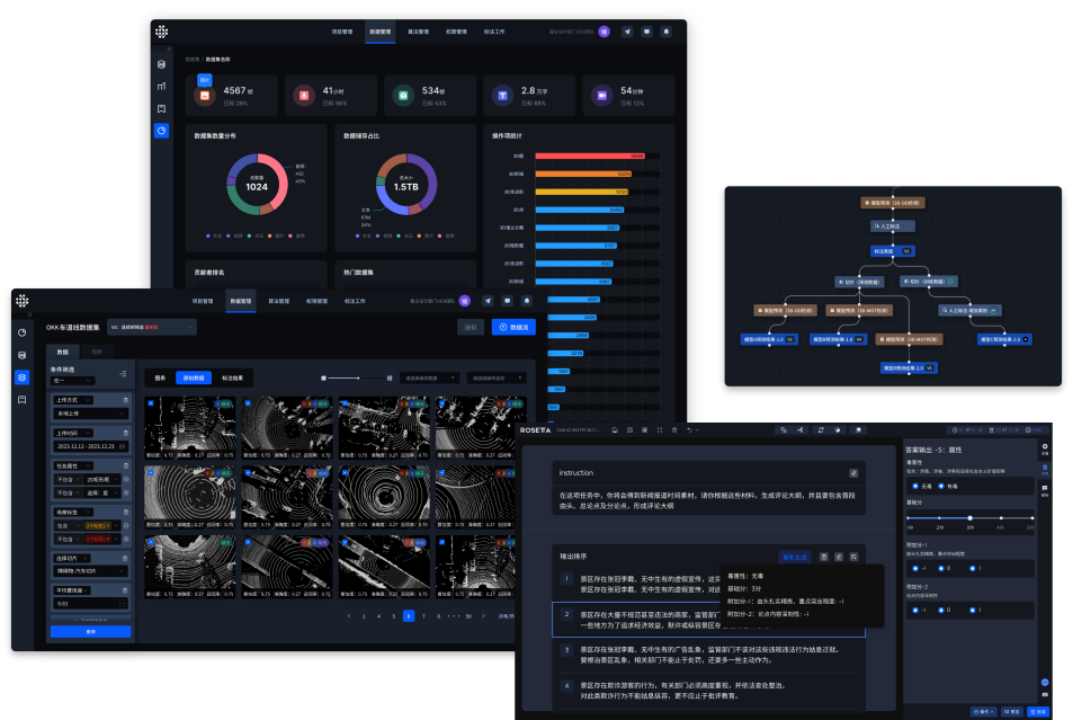
▲AI数据发现、管理、协作、迭代平台Morningstar
针对这些痛点,星尘数据自主研发了AI数据全生命周期管理功能,强化数据版本控制、快捷数据切片、可追溯数据血缘和安全管控。

▲语义检索
通过数据全生命周期可视化管理,MorningStar确保数据运营统一管理和快速迭代;支持灵活数据切片、多模态、自定义数据检索,挖掘数据价值,快速提取特殊场景数据;同时,集成主流难例数据发现策略,如主动学习等,为算法工程师提供数据特征分布、可视化和挖掘、模型指标计算等便捷功能。此外,MorningStar汇聚数据资产及使用数据,实现企业数据资产管理,使团队协作更安全、数据迭代可追溯,打破企业内部的“数据孤岛”,助力企业在AI 成本投入、算法精度和数据应用能力提升等方面。
谈及未来,章磊展望道,星尘数据将不仅用MorningStar助力AI 2.0发展,还将持续以数据为中心,推出新的功能和服务,发现数据价值,加速AI创新。